
Table of Contents
Regardless of the infrastructure you are running, it is always important to keep an eye on your costs. There have been enough horror stories of cloud billing getting out of control that teams should have some measures in place to keep an eye on the usage of these resources to avoid surprises. Beyond this, there are other benefits to monitoring the usage and cost of your infrastructure. Having access to this extra data might be informative further down the line when making decisions about upgrading or scaling your infrastructure.
In this article, you will learn how to set up Grafana and Prometheus to monitor your Kubernetes cluster. Like Kubernetes, Prometheus is a graduate of the Cloud Native Computing Foundation. It is an open-source monitoring system that integrates with many other tools and systems to collect data. Grafana, another open-source project, acts as a dashboard and visualizer for various data sources, including Prometheus, for which it boasts first-class support. With these two tools, you should be able to glean some helpful insights about the usage of your cluster.
#Setting Up Prometheus Operator
While it is possible to install and manage Prometheus and Grafana independently as standalone applications and connect them after the fact, there is quite a lot of configuration boilerplate involved, which can all be abstracted away by using Prometheus Operator. Specifically, for this guide, you can use kube-prometheus-stack, a Helm chart that handles setting up Prometheus Operator, as well as Grafana. This Helm chart will give you a functional monitoring stack with minimal configuration required, making it an excellent way to experiment with these tools. It is also suitable for setting them up for a long-term deployment if you do not have any existing components for your monitoring stack.
Before getting started, make sure you have the prerequisites installed. If you are using kube-prometheus-stack, all you will need is a Kubernetes cluster and Helm 3.
It’s recommended to use a non-default namespace for these resources to make things easier to manage further down the line. You can create a new namespace like so:
kubectl create namespace monitoring
The chart you are going to install exists within the prometheus-community repo, so you’ll need to add that before you can install the chart:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
Next, to see what charts are available in this newly added repo, you can use the search command:
helm search repo prometheus-community
This will give some output like so:
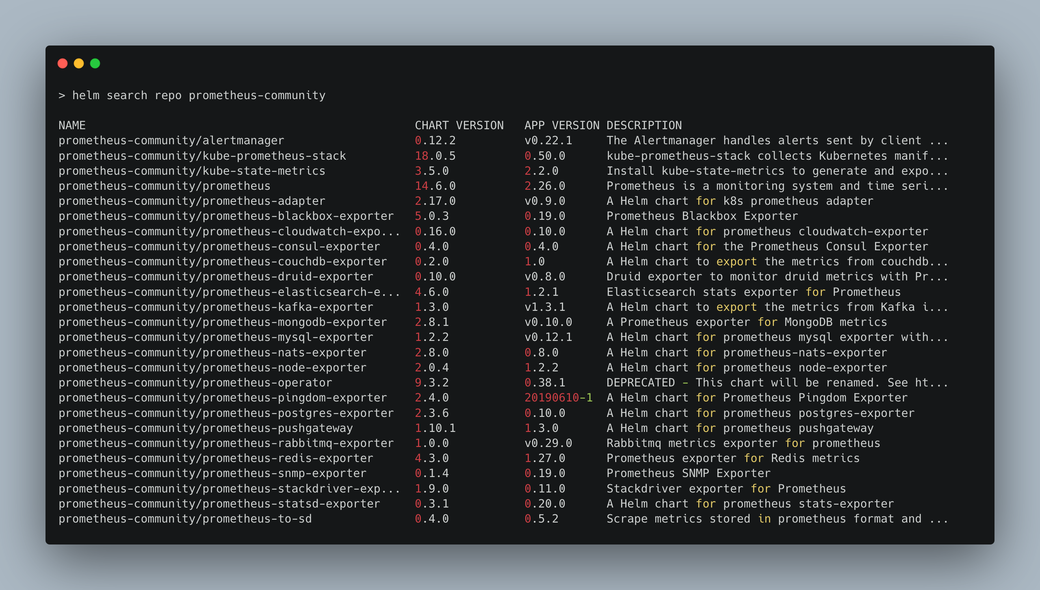
The one that you will want to install is kube-prometheus-stack. You can install that in the namespace you just created with the following command:
helm install prometheus-stack --namespace monitoring prometheus-community/kube-prometheus-stack
This command will run for a bit while it sets up all the required resources, but once the command completes, you can verify everything is present by running:
kubectl get pod --namespace=monitoring
This should produce some output like so:
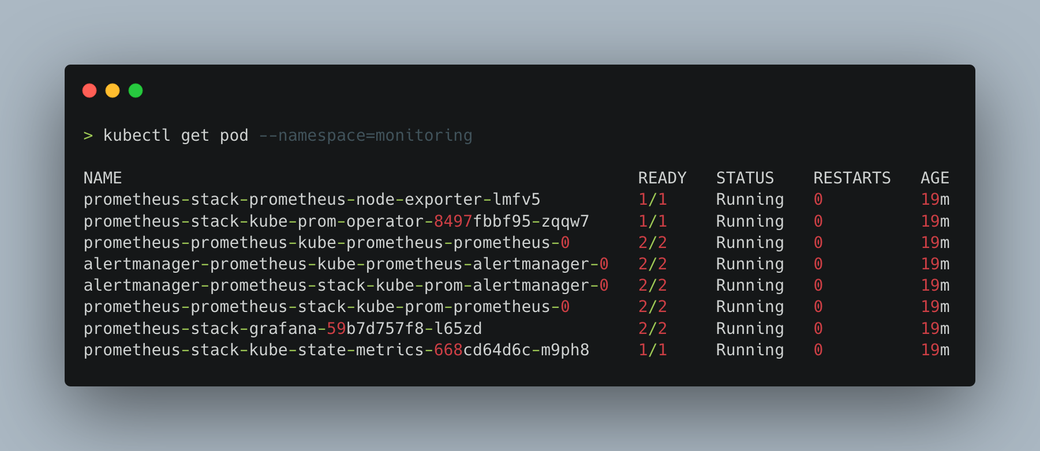
Now you have a monitoring stack running on your cluster. As you can see, there are multiple components required for everything to work, and it would take quite a bit of manual configuration to get to this same point without using the Helm chart. From this output, the two Pods which you will want to take a look at are:
prometheus-stack-grafana-*- the Grafana dashboardprometheus-prometheus-kube-prometheus-prometheus-0- the Prometheus instance
By default, there is no ingress configured for these Pods, but to get going quickly, you can port-forward traffic from the machine you are running kubectl on, allowing you to access the Pods. For Grafana, you will need to port-forward port 3000, and for Prometheus, it will be 9090. You can do this with the following commands (which are long-lived, so you will need to run them in separate terminal panes/windows):
kubectl port-forward <prometheus-pod> 9090 --address=0.0.0.0
kubectl port-forward <grafana-pod> 3000 --address=0.0.0.0
With these two commands running, you can access Prometheus and Grafana by navigating to the associated port on the kubectl client machine. This is fine for exploratory purposes, but it would be a good idea to use proper ingresses to expose these services for a long-term deployment.
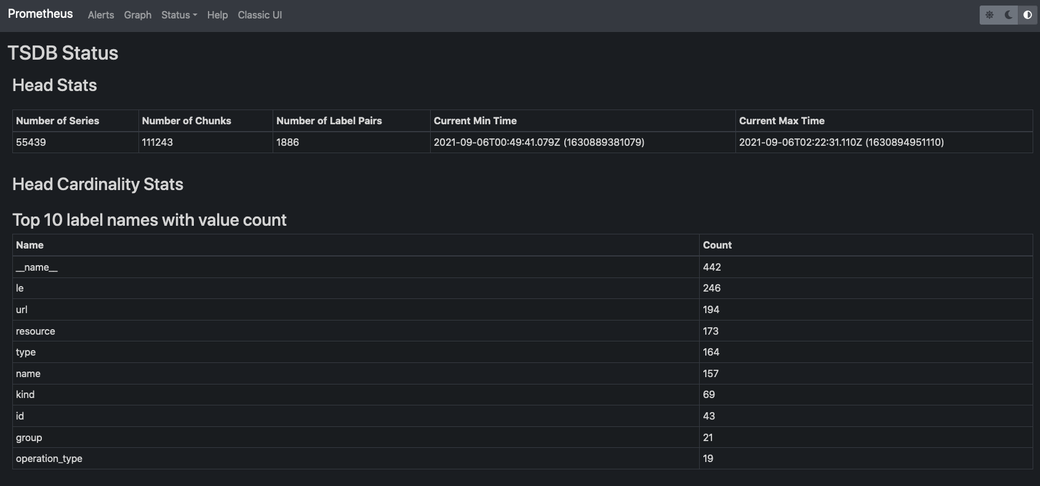
You should see the Prometheus web interface if you navigate to port 9090 on your kubectl client machine. From the nav menu at the top, select status > TSDB status. From this page, you can see an overview of the data stored within Prometheus’ DB. This is a good way to quickly check that things are working as expected because if Prometheus is misconfigured, there will likely be no data here. If it is working, it will quickly be populated with quite a lot of data, as you can see here:
Next, navigate to port 3000, and your browser should present you with the Grafana login screen. When installed as described above, the default username and password should be “admin” and “prom-operator”.
kube-prometheus-stack includes several pre-configured dashboards in its Grafana instance, which is a nice bonus, as you can see quite a lot of detailed information about your cluster straight out of the box. Once you are logged in, from the left-hand menu, select Dashboards > Manage to see the preconfigured dashboards.
Now that your Grafana instance has access to your cluster’s metrics, you can use this data to gather insights about your Kubernetes usage, and subsequently, its cost. None of the preconfigured dashboards are specifically about cost, but you can create your own with some effort.
#Monitoring Your Cost
This step will likely take a bit of trial and error to find the right combination of metrics to track and the right formula to get the insights you are after. To get some quick and easy results, you can start by aggregating basic resource usage metrics for CPU, RAM, and storage. These values can then be multiplied by whatever your hourly rate is for the resource in question. For example, if you are using Google Cloud Platform’s GKE service, pricing information can be found here.
The preconfigured dashboards that come with kube-prometheus-stack are worth looking at because they will give you some context for getting meaningful insights out of your data. For example, by looking at the included “Kubernetes / Compute Resources / Cluster” dashboard, you can see how CPU usage is calculated using a metric called container_cpu_usage_seconds_total.
Create a new dashboard by selecting the Create > Dashboard option in the left-hand menu. Next, you can add a new panel and enter the following PromQL in the provided field:
(sum(container_cpu_usage_seconds_total) / 60 / 60 ) * 0.0445
This should aggregate the CPU usage of your containers and convert it to hours, which can then be multiplied by the CPU/hr cost from GCP to get something like this:
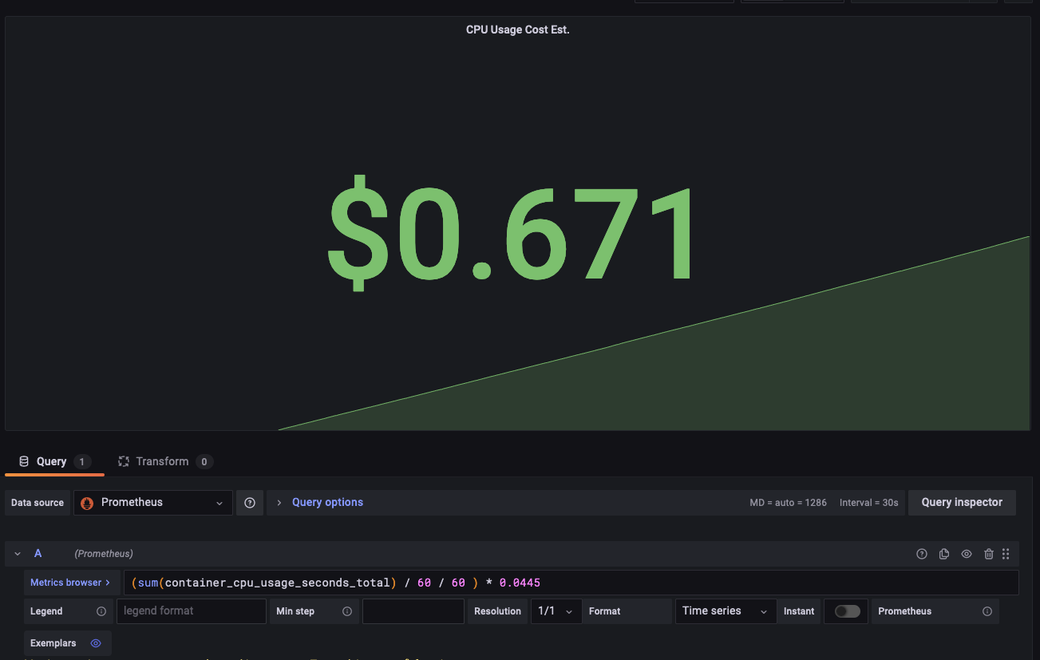
Because this is a new cluster with a minimal workload, the cost is still low, but you can see that it steadily increases at a consistent rate. Using this approach, you can experiment with the data available to you and build a collection of charts to monitor your cluster costs.
This approach has some benefits and limitations. On the plus side, all the tools required are free and easy enough to set up. You retain complete control of your data and can extend it however you like to create your ideal cost-monitoring system. The obvious drawback is that a fair bit of manual effort is involved (and even more so if you opt to set up Prometheus and Grafana manually instead of with the Helm chart). Furthermore, the quality of the insights you get will be directly linked to how much time and effort you invest in configuring and optimizing your dashboards.
#Alternative Options
There are some alternatives and additions which you should consider when setting all this up. Just as the Helm chart saves a lot of effort when setting up Prometheus, there are some pre-built solutions for monitoring resource usage costs with these tools. One excellent option is Kubecost, which offers Grafana dashboards built specifically for this purpose. The dashboards come preconfigured with an opinionated setup for monitoring cluster cost with GCP, so some tweaking may be required to get it working with your specific setup, but it is certainly worth taking a look at to see how they set things up.
When it comes to managing your resource usage cost, monitoring is only half the puzzle. To actually get some benefit out of it, you need to have an actionable plan based on your data. This is where services like Loft.sh come in. Loft’s Kubernetes platform has features to help manage your resource costs. Of particular note is sleep mode, which can scale down your non-prod virtual clusters when not in use to save resources and, therefore, money.
There are countless options available for setting up cost monitoring for your cluster. There is generally something for everyone, depending on how much time and effort you want to invest in your monitoring solution up-front. One of the nice things about software is that it is generally easy to change, so it very well could be worth your while to implement a low-effort solution with preconfigured tools like Prometheus Operator and Kubecost to determine if there is value there for you. From this evaluation, you will be in a better position to make long-term decisions about the direction you want to take for your cost monitoring and Kubernetes resources.







