

Table of Contents
#vcluster Series
- Introduction to Virtual Clusters in Kubernetes
- Kubernetes Namespaces vs. Virtual Clusters
- vcluster Hands-on Tutorial
- High Availability with vcluster
- Virtual Clusters For Kubernetes - Benefits & Use Cases
- Development Environments with vcluster
- How Virtual Kubernetes Clusters Can Speed Up Your Local Development
- Using Virtual Clusters for Development and CI/CD Workflows
- Kubernetes: Virtual Clusters For CI/CD & Testing
- How Codefresh Uses vcluster to Provide Hosted Argo CD
If you need to spin up a Kubernetes environment to run your end-to-end tests, what do you do? Of course, you want your setup to mirror production, but starting a Kubernetes cluster (or multiple clusters) is resource-intensive and slow. So, you might consider using a namespace to achieve this kind of isolated environment in an already running cluster.
Namespaces are relatively isolated environments that run inside a single physical Kubernetes cluster. You can create a new environment for each of your test runs with namespaces, but they come with limitations.
For example, if your application needs to create cluster-scoped resources (nodes, persistent volumes, storage classes, etc.), namespaces aren’t a good fit. They can only access these resources through your host cluster, which won’t work if you need true isolation between environments.
Virtual clusters (or vclusters) are another solution for creating a cluster within a Kubernetes cluster. Virtual clusters create a stronger separation of concerns while maintaining access to cluster-level resources that namespaces cannot access in isolation.
Both namespaces and virtual clusters are essential tools for running isolated Kubernetes workloads, but the distinction can be significant. This article will look at the pros and cons of using namespaces and virtual clusters in Kubernetes. Along the way, you’ll learn about specific use cases for each so you can make the best decision in your situation.
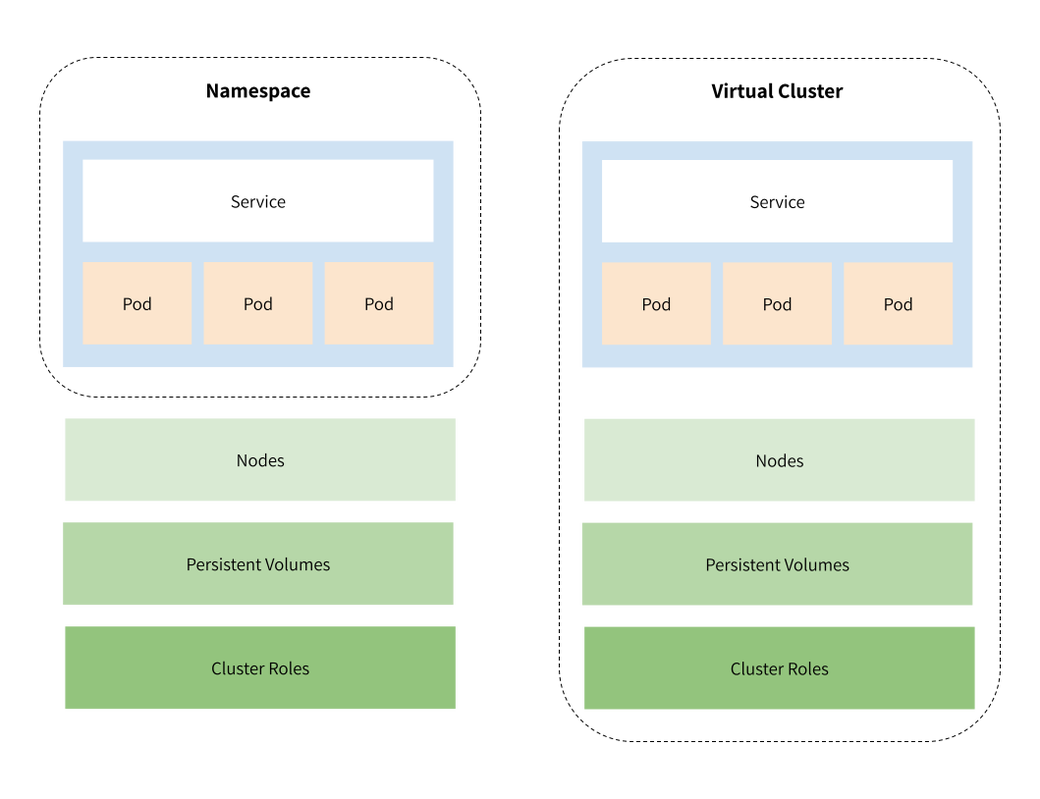
#Namespaces
Namespaces are designed to divide clusters into environments where users are spread across several teams or projects that all share the same Kubernetes cluster. They have separate services and pods and provide a scope for naming resources but cannot be nested inside each other and may still communicate with one another.
#Why Use Namespaces?
If you run a complex application with many teams that deploy applications independently and have many dedicated resources, your default namespace will quickly become hard to navigate. In addition, having hundreds of services running in a single namespace makes it hard to understand what’s connected, so namespaces are an excellent way to logically group resources inside your cluster.
Microservices are a good use case for namespaces. They help avoid naming collisions and encourage separation of concerns by making it harder for multiple services to use the same database. At the same time, you can share some resources when it makes sense.
Another common use case for namespaces is to separate staging and development environments. For example, if you’re using an Elastic stack for logging, you can deploy it in one cluster and use it for both environments. There are some significant drawbacks to this approach (which I’ll address in the next section), but it’s worth pointing out as it’s commonly used.
Namespaces enable the division of a cluster’s resources between multiple teams, but they also allow you to implement resource quotas.
So, let’s say you have a development cluster with limited resources, and you want to give each team a share of its resources for their application. You can define resource quotas per namespace that limit how much CPU or RAM each namespace can use. This prevents situations where one team’s application consumes so much memory that other parts of your application start to fail.
Finally, namespaces enhance role-based access controls. For example, permissions can be set such that a team can create, update, and delete resources in their namespace, but they cannot do similar operations in other namespaces. This minimizes the risk of a new engineer accidentally interfering with another team’s application.
#Limitations of Namespaces
While namespaces are a good tool for some light isolation, they are not complete Kubernetes clusters on their own, which means that you run some serious risks and limitations when you rely on namespace-based isolation.
First, all your namespaces use the same Kubernetes control plane, so the API server, etcd, scheduler, and controller-manager are shared between namespaces. Unfortunately, this means that you can’t run custom configurations on any of the Kubernetes-level resources within a namespace.
Second, some components in Kubernetes are not namespaced. They live just globally in the cluster, and you can’t isolate them using namespaces. For example, persistent volumes are accessible throughout your whole cluster. So even if you isolate your Elastic logging service mentioned above, a service in another namespace could connect to the same volume and read or write data to it.
This limitation applies to other important resources like ingress controllers, nodes, and storage classes too. So, if one of your microservices needs to spin up new nodes based on increased load, you can’t do it at the namespace level - you’ll need to do it at the Kubernetes cluster level.
Teams who need a higher level of configurability or better isolation between resources often have to set up multiple clusters. As mentioned above, that can be expensive and much slower to spin up. Each cluster has to create an additional API server, controller manager, etcd, and kubelet just to get going.
Fortunately, there is another solution: virtual clusters.
#Virtual Clusters
Virtual Kubernetes clusters allow you to spin up a new Kubernetes cluster inside an existing one. This virtual cluster achieves a higher degree of isolation and enables you to run more customizable Kubernetes environments without provisioning new physical clusters every time.
While there are a few different ways to run virtual clusters, a popular solution from Loft Labs uses a lightweight Kubernetes implementation called k3s within your existing Kubernetes cluster. clusters run within a namespace, have a virtual identity, and use their own core Kubernetes resources, which are synced with the host cluster.
“Besides the synchronization of virtual and host cluster resources, the hypervisor also redirects certain Kubernetes API requests to the host cluster, such as port forwarding or pod/service proxying. It essentially acts as a reverse proxy for the virtual cluster.” - Introduction to Virtual Clusters
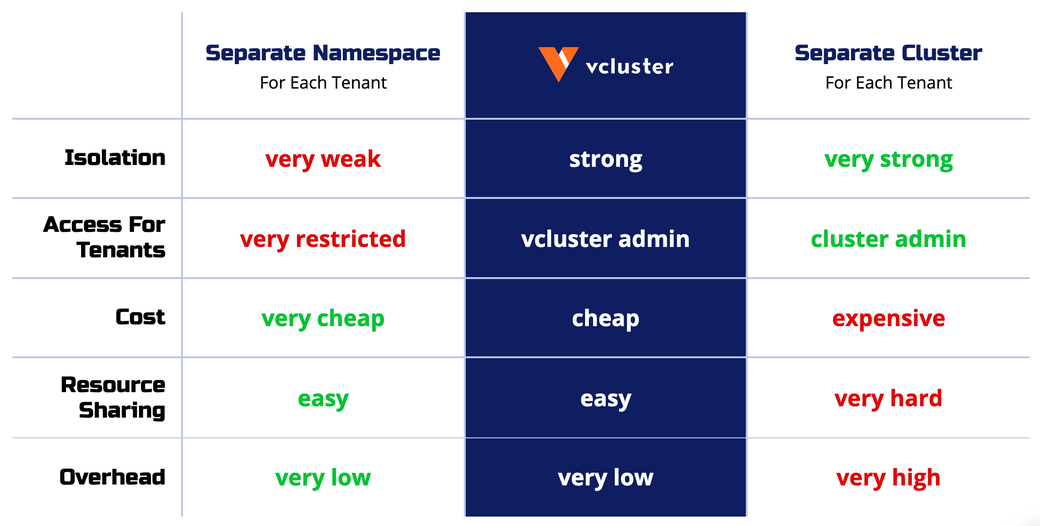
#Why Use Virtual Clusters?
Virtual clusters solve many of the problems that namespaces present.
Because you can have multiple virtual clusters within a single namespace, they are much cheaper than the traditional Kubernetes clusters, and they require lower management and maintenance efforts. This makes them ideal for running experiments, continuous integration, and setting up sandbox environments.
Virtual clusters also provide more stability than namespaces in many situations. The virtual cluster creates its own Kubernetes resource objects, which are stored in its data store. The host cluster has no knowledge of these resources.
Isolation like this is excellent for resiliency. As mentioned above, engineers who use namespace-based isolation can still access Kubernetes-level resources like persistent volumes or the etcd configuration. If an engineer breaks something in one of these shared resources, it will likely fail for all the teams that rely on it.
Finally, virtual clusters can be configured independently of the physical cluster. This is great for multi-tenancy, like giving your customers the ability to spin up a new environment or quickly setting up demo applications for your sales team.
Achieving Network, Namespace, and Cluster Isolation in Kubernetes with vcluster. In this article you’ll learn how to implement security measures necessary to ensure proper isolation, using Kubernetes native resources as well as Loft’s virtual clusters.
#Limitations of Virtual Clusters
While virtual clusters provide a level of isolation greater than that given by namespaces, they also have their limitations. First, because they run on the same host cluster, they’re not appropriate for situations of very low trust - traditional clusters will still give you a greater degree of isolation.
Virtual clusters also don’t support all Kubernetes features at the moment. For example, virtual storage classes, container runtimes, and network plugins are unavailable in vclusters, so you either have to limit access to these features within your application or fall back to the host cluster.
#Running Virtual Clusters
To get started with vclusters, check out Loft. It runs on any Kubernetes host and can be installed in just five minutes.
Loft builds a new namespace and a lightweight cluster inside the namespace when creating a virtual cluster. Then, the vcluster’s hypervisor syncs the Kubernetes resources between the virtual cluster and your underlying host cluster.
Your developers can use this virtual cluster anytime they need an isolated environment. Because they don’t have the same level of access to the host cluster, you can be confident that they’re not likely to take down your whole application with a bad deployment.

To help you save on infrastructure costs, Loft also offers a sleep mode that will scale down your vcluster’s resources automatically. To get started, check out the Loft Quickstart guide.
#Conclusion
Namespaces are sometimes an acceptable choice for running multiple environments within a cluster. They provide limited user permissions, usage quotas, and some isolated resources within Kubernetes. Just be sure to learn about the best practices and limitations before you go too far down that path.
Virtual clusters improve on namespaces in many ways by providing more substantial isolation for a more stable, resilient, and flexible Kubernetes environment. They can be used for both development and production workloads and help you save money versus traditional clusters. To learn more or get started with virtual clusters, check out Loft.
#Additional Articles You May Like:
- Kubernetes Namespace: The What, Why, and How
- Leveraging Namespaces for Cost Optimization with Kubernetes
- Kubernetes Network Policies for Isolating Namespaces
- Kubernetes Multitenancy: Why Namespaces aren’t Good Enough
- Kubernetes Multi-Tenancy: Why Virtual Clusters Are The Best Solution
- Introduction to Virtual Clusters in Kubernetes
- A Hands-on Tutorial: Kubernetes Virtual Clusters
- [Video] Beyond Namespaces: Virtual Clusters are the Future of Multi-Tenancy







