Table of Contents
Today, we broke the news about raising our latest round of funding, and in this blog post, I want to share a bit of additional context regarding why we are building this company, the journey of how we got here, and what the road ahead looks like. While we maintain quite a few open source projects and I definitely want to shed some light on why we’re doing this and how these projects tie together, let’s first talk about our most prominent project: vCluster – our technology for virtualizing Kubernetes clusters. We launched it as an open source project in April 2021, and it has been the bedrock of our company’s success ever since.
#Why Virtual Kubernetes Clusters?
If this funding announcement is the first time you heard about virtual Kubernetes clusters, you may wonder what that means, or you may even think “Isn’t Kubernetes virtualized already?” - You’re definitely right that a majority of Kubernetes clusters run on virtual machines and launch workloads as pods via container technologies such as Docker as yet another abstraction layer. So, what exactly do we mean by virtualizing Kubernetes?
Virtual Kubernetes is not so much about how workloads are launched but rather about virtualizing Kubernetes itself. Virtual machines allow you to create more dynamic logical servers without having to deploy separate physical machines each time that will likely end up being underutilized. Virtual clusters allow you to do something similar. They allow you to fulfill the increasing demand for Kubernetes clusters without ending up with thousands of underutilized and heavyweight “real” Kubernetes clusters.
#Platform Teams Are Facing A Huge Demand For Kubernetes
If your organization is heavily building on top of Kubernetes these days, there is a high chance that you won’t just have a single Kubernetes cluster for the entire company. Instead, it’s highly likely that you’re operating many clusters for many different teams and use cases. Especially in large companies, this can mean that the infra or platform teams need to spin up and manage hundreds or even thousands of clusters. What’s even more interesting though is that many organizations observe that the number of clusters their organization needs is growing significantly each year because the demand for Kubernetes continues to grow. This demand can stem from many different use cases, including the need to create:
- Separate clusters for engineers to develop, test, and debug Kubernetes-based applications
- Separate clusters for running externally developed, packaged software that you deploy for internal use
- Separate clusters for hosting customer environments when you’re selling your software as a managed service
- Separate clusters for hosting POC/playground environments for customers to evaluate out your software or test new versions of it
- Separate clusters as sandbox environments for testing infrastructure changes or for conducting internal trainings
- For cloud providers and hosting companies: Separate clusters for each customer when managed Kubernetes is literally the product you are selling
Over the past 3 years, we have seen many more of these use cases and I sometimes feel like we are discovering new ones every day. If your company is using Kubernetes, you will likely have encountered at least one - or probably multiple - of these scenarios and you might also see the demand for Kubernetes in your organization increase over time as new use cases emerge and engineers intensify their use of Kubernetes.
#Fleet Management Isn’t The Answer
To fulfill the demand for Kubernetes, many organizations are deploying a huge number of Kubernetes clusters. Some do it in a rather trivial and unstructured way where clusters are spun up with a plethora of different tools, others are more sophisticated and invest into fleet management to keep clusters in sync as much as possible and to enforce common standards across the org, and some infra teams invest heavily in IaC and GitOps solutions to organize all of these clusters.
However, no matter how sophisticated your fleet management is to keep your 1,000 clusters in sync, you’re still facing the ugly reality of running 1,000 clusters and no degree of automation can fix the downsides of this approach:
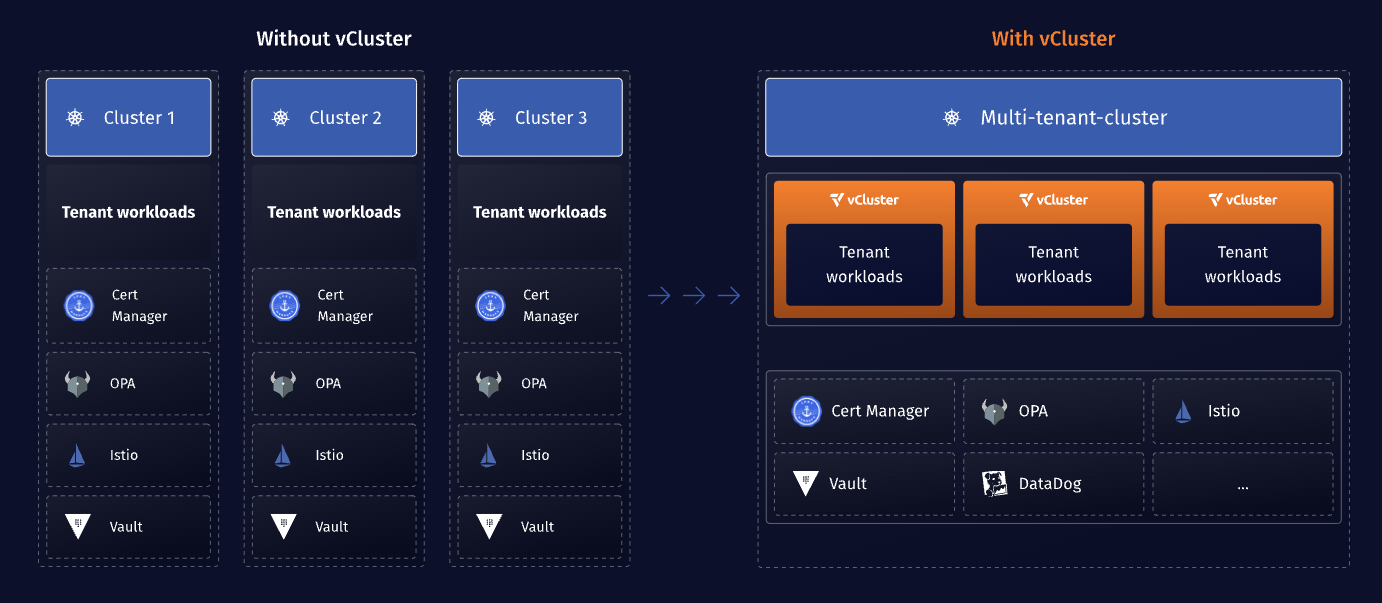
- Replicated Platform Stack: Running 1,000 separate clusters typically means that you’ll need to run all of your cluster-wide standard components separately for each cluster, which could mean running rather heavyweight pieces of software such as Istio, OPA and others 1,000 times.
- Fixed Cluster Cost: Each cluster needs a control plane that typically costs ~$900/year in many public clouds plus a set of nodes to run the platform stack components that you’ll likely deploy to each cluster. The cost for a single cluster can add up to thousands of dollars before you even deploy the actual application you created this cluster for.
- Idle & Underutilized Clusters: Especially pre-production clusters run idle the majority of the time. While you can autoscale your own application in many cases, unfortunately, it’s almost impossible to dynamically scale an entire cluster with all of its platform stack down to zero when nobody is using the cluster, so you’ll keep paying the fixed cost for each cluster no matter if it’s actually used or just runs idle over nights and weekends.
- On-Hold / Forgotten Clusters: If IT teams hand out a cluster to a particular team, it’s rare that the team raises their hand immediately when the cluster may not be needed anymore. More often, teams hold on to their clusters in case their need resurfaces later on again and sometimes, nobody in the organization can even remember what this cluster was intended for and whether it may still be actively used or not.
- Autonomy & Responsibility Challenges: While IT and platform teams often create clusters and deploy the platform stack, when they hand them over to the application-focused teams, the question arises whether these teams should be granted full cluster access with a lot of autonomy but also the responsibilities that come with this level of access or whether to manage the cluster for them in order to retain control and enforce standardization across the organization. Neither path seems ideal.
While the majority of the industry has overlooked these challenges initially, the further companies advance in their Kubernetes journey the more they feel the pain associated with these issues. That’s why we’re advocating for an architectural shift from single-tenant clusters to multi-clusters clusters and we invented vCluster as virtualization technology that makes it easier and more secure to set up multi-tenant Kubernetes clusters.
#Inventing Virtual Kubernetes Clusters
Containerization as the second most influential abstraction layer after virtual machines largely became popular in the form of the Docker runtime, a technology that was born as part of dotCloud, which was a Platform-as-a-Service (PaaS) offering that ultimately failed and shut down. It feels like history is repeating sometimes because back in 2019, way before we had the idea for building vCluster, my co-founder Fabian and I also worked on a PaaS offering. And just like dotCloud, our product ultimately failed as well but the experience of building it helped us feel the pain of running large multi-tenant Kubernetes clusters and gave us a unique insight into why we believe most companies ended up creating small single-tenant clusters instead of embarking on the multi-tenancy path. However, if you consider that Kubernetes is designed to be a large-scale distributed system and most of the CNCF projects out there are also designed to run at a significant scale, it feels like creating smaller 3-5 node clusters is not the best way to leverage these technologies. With this tension right in front of our eyes, we decided to pivot and set out to find a solution that would solve the challenges associated with Kubernetes multi-tenancy. After launching a first open source project called Kiosk to provide a preliminary solution and a subsequent year of R&D and piloting with early adopters, we ultimately launched vCluster in 2021.
While every Kubernetes platform focused on more tooling around fleet management, we advocated for an architectural change from small single-tenant clusters back to large clusters. If you remember the architectural shift toward containerization, you probably also remember all the concerns many engineers had, including questions such as “Is this as secure as our VMs?” or “Why do we need another layer?” - With virtual clusters, we faced a similarly sophistical and curious but also skeptical audience. However, once you help people see why this additional layer of abstraction makes sense, show how easy it is to use it and explain the benefits, the question quickly shifts towards “What else can I do with this?” and today, we’re discovering new interesting use cases for vCluster every day. One of the most fascinating ones for me has been when we saw the first company to spin up multiple virtual clusters for every pull request as part of their CI pipelines to validate their software against multiple versions of Kubernetes. Can you imagine launching 10 EKS clusters on-demand for each pull request? That would likely add hours to each CI run and it would be cost prohibitive as well. But with virtual clusters, which can be launched in a single container, you can fire up 10 clusters in seconds and dispose of them again after the CI run completes. Truly ephemeral Kubernetes clusters - a use case we didn’t even think about when we started working on vCluster 3 years ago.
#The Impact of vCluster So Far
When I gave the first ever conference talk about vCluster with the title “Beyond Namespaces,” the audience at KubeCon NA in Los Angeles back in 2021 was quite excited and the project has come a long way since then. Today, vCluster has over 100 contributors and over 5,000 GitHub stars. Our Slack community counts over 3,000 members, the community has spun up over 40 million virtual clusters, and some of the largest companies in the world are using vCluster.
This open source success story has also fueled our growth as a company. We grew our recurring revenue by 4.6x over the past 12 months, doubled our headcount, and can count a growing number of companies to our customer base, ranging from fast growing startups like CoreWeave and Atlan to five Global Fortune 500 companies across different industry verticals.
#Our Commitment To Open Source & To Our Community
We are fortunate to have an amazing community of users and supporters that ensure that vCluster and our other open source projects continue to grow and thrive. Our open source projects and the community that surrounds them are essential parts of our company’s DNA and we’re committed to steering our projects in a direction that enables our users to be successful with our technology. I am thankful for each and everyone who has been part of our community and I’m looking forward to many more users to join. If you’re not a part of it yet but want to get involved, joining us on Slack is a great first step.
#The Road Ahead
As part of this funding announcement, we are also launching vCluster v0.20 as a beta version. This release introduces the vcluster.yaml as a new configuration format that makes configuring virtual clusters easier than ever before and introduces things like the well-defined schema spec for vcluster.yaml which allows for solid config parsing and validation, makes future migrations easier and offers convenience features such as autocomplete in any IDE. This will make it even easier to define virtual clusters as-code and make them reproducible. As part of this change, we also overhauled the documentation and made it much easier to navigate along the definition of the vcluster.yaml format.
Delivering Kubernetes efficiently for all kinds of use cases has definitely been one of the biggest challenges and priorities for platform engineers over the past couple of years and we’re excited to provide an essential building block for organizations to tackle this topic. However, besides our continued investment in vCluster, we also launched DevPod as another important building block that helps to streamline and deliver consistent dev environments in any infrastructure and we expect that this topic will continue to gain traction, so we are committed to continue innovating in this area as well. Identifying the challenges platform engineers face and offering best-in-class, highly innovative solutions in form of easily adoptable building blocks to integrate into your platforms is at the core of what we aim to do and vCluster, DevPod and our other projects are just the start of this journey.
I am incredibly proud of my team and of everything we have accomplished over the past couple of years. With the backing of Khosla Ventures and a fresh round of funding, our team is as enthusiastic as ever and I cannot wait to see where this journey will take us. Thanks to everyone who has been supporting us along the way and thanks to our investors for their trust in us.